Self-Attention and Multi-Headed Attention
Implementing self-attention and multi-head attention mechanisms as part of the Transformer architecture
Paper Link
Code
Multi-Headed Attention (numpy)
import numpy as np
def compute_qkv(X, W_q, W_k, W_v):
Q = np.dot(X, W_q)
K = np.dot(X, W_k)
V = np.dot(X, W_v)
return Q, K, V
def self_attention(Q, K, V):
d_k = Q.shape[1]
attention_scores = np.matmul(Q, K.T) / np.sqrt(d_k)
score_max = np.max(attention_scores, axis=1, keepdims=True)
attention_weights = np.exp(attention_scores - score_max) / np.sum(np.exp(attention_scores - score_max), axis = 1, keepdims = True)
return np.matmul(attention_weights, V)
def multi_head_attention(Q, K, V, n_heads):
d_model = Q.shape[1]
assert d_model % n_heads == 0 # ensure d_model is divisble by n_heads
d_k = d_model // n_heads
# Reshape Q, K, V to separate heads
# original d_model is spilt into (n_heads, d_k)
Q_reshaped = Q.reshape(Q.shape[0], n_heads, d_k).transpose(1, 0, 2) # transpose to (n_heads, seq_len, d_k) from (seq_len, n_heads, d_k)
K_reshaped = K.reshape(K.shape[0], n_heads, d_k).transpose(1, 0, 2)
V_reshaped = V.reshape(V.shape[0], n_heads, d_k).transpose(1, 0, 2)
attentions = []
for i in range(n_heads):
attn = self_attention(Q_reshaped[i], K_reshaped[i], V_reshaped[i]) # Compute attention for the i-th head
attentions.append(attn)
# Concatenate along the columns axis
attention_output = np.concatenate(attentions, axis=-1)
return attention_outputMulti-Headed Attention with Masking (Decoder) (PyTorch)
import torch
import torch.nn as nn
from torchtyping import TensorType
class MultiHeadedSelfAttention(nn.Module):
def __init__(self, embedding_dim: int, attention_dim: int, num_heads: int):
super().__init__()
torch.manual_seed(0)
if attention_dim % num_heads != 0:
raise ValueError(f"attention_dim ({attention_dim}) must be divisible by num_heads ({num_heads})")
head_size = attention_dim // num_heads
self.heads = nn.ModuleList([
self.SingleHeadAttention(embedding_dim, head_size)
for _ in range(num_heads)
])
pass
def forward(self, embedded: TensorType[float]) -> TensorType[float]:
# apply each head, collect [batch, seq, head_size]
head_outputs = [head(embedded) for head in self.heads]
concat = torch.cat(head_outputs, dim=2)
return torch.round(concat * 10_000)/10_000
class SingleHeadAttention(nn.Module):
def __init__(self, embedding_dim: int, attention_dim: int):
super().__init__()
torch.manual_seed(0)
self.key_gen = nn.Linear(embedding_dim, attention_dim, bias=False)
self.query_gen = nn.Linear(embedding_dim, attention_dim, bias=False)
self.value_gen = nn.Linear(embedding_dim, attention_dim, bias=False)
def forward(self, embedded: TensorType[float]) -> TensorType[float]:
k = self.key_gen(embedded)
q = self.query_gen(embedded)
v = self.value_gen(embedded)
scores = q @ torch.transpose(k, 1, 2) # @ is the same as torch.matmul()
context_length, attention_dim = k.shape[1], k.shape[2]
scores = scores / (attention_dim ** 0.5)
lower_triangular = torch.tril(torch.ones(context_length, context_length))
mask = lower_triangular == 0
scores = scores.masked_fill(mask, float('-inf'))
scores = nn.functional.softmax(scores, dim = 2)
return scores @ vAttention Demo
Self-attention playground
Pick a query token, toggle masking, and see how the attention weights and context vector change for a single head.
Notes
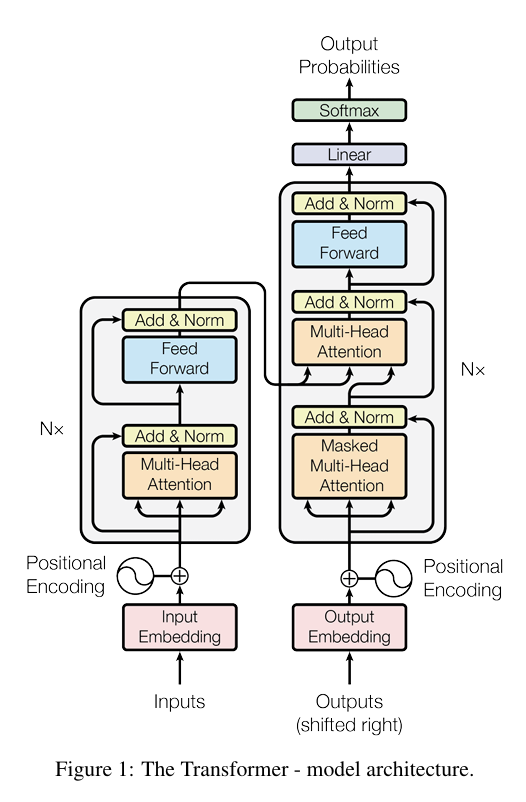
Architecture Overview
The Transformer replaces recurrence with attention mechanisms that allow every token to directly attend to every other token in parallel. This dramatically shortens gradient paths and enables efficient parallelization during training.
Query, Key, Value (Q/K/V)
For each token, we create three representations through learned linear projections:
- Query (Q): what information this token seeks from others
- Key (K): how this token advertises itself to queries
- Value (V): the actual content to be mixed and aggregated
The attention mechanism computes similarity scores between queries and keys (), then uses those scores as weights to create a weighted sum of values.
Scaled Dot-Product Attention
The core attention operation follows these steps:
-
Score computation:
- Dot product measures similarity between each query-key pair
- Division by prevents scores from growing too large as dimension increases, keeping softmax gradients stable
-
Softmax normalization: each row is converted to a probability distribution (sums to 1)
- Each token creates a weighted average over all positions
-
Value aggregation: multiply attention weights by to get the final output
- Each position receives a context-aware mixture of value vectors
Types of Attention
Self-Attention
All three components (Q, K, V) come from the same sequence. Each token attends to all tokens in its own sequence to build context-aware representations.
Use case: Both encoder and decoder use self-attention to understand relationships within their respective sequences.
Multi-Head Attention
Instead of one attention operation, we run multiple attention heads in parallel:
- Split into heads, each with dimension
- Each head learns different patterns: one might capture syntax, another coreference, another positional relationships
- Outputs are concatenated and linearly projected:
Intuition: Multiple "representation subspaces" let the model simultaneously attend to different types of information.
Masked Self-Attention (Decoder)
Same as self-attention, but with a causal mask that prevents position from attending to future positions (). Implemented by setting future positions to before softmax.
Why: During training/generation, the decoder should only use past context to predict the next token.
Cross-Attention
Queries come from one sequence (decoder), while keys and values come from another sequence (encoder output):
- ,
- Allows decoder to focus on relevant parts of the source/input sequence
- This is the "encoder-decoder attention" that enables translation, summarization, etc.
Encoder–Decoder Architecture
Encoder Stack
Each encoder layer contains:
- Multi-head self-attention: tokens attend to all encoder positions (bidirectional)
- Feed-forward network: two-layer MLP applied independently to each position
- Residual connections: around each sub-layer ()
- Layer normalization: stabilizes training by normalizing across features
The encoder processes the entire input in parallel, building rich contextual representations.
Decoder Stack
Each decoder layer contains:
- Masked multi-head self-attention: tokens attend only to current and previous positions (causal/autoregressive)
- Cross-attention: queries from decoder attend to encoder output (keys & values)
- This is how the decoder "reads" the source sequence
- Feed-forward network: same as encoder
- Residual connections + layer norm: applied around all three sub-layers
The decoder generates output autoregressively, one token at a time during inference.
Residual Connections & Layer Normalization
Residual connections () create "shortcut" paths that:
- Enable gradient flow through deep networks (mitigates vanishing gradients)
- Allow the model to learn incremental refinements rather than completely new representations
- Each layer can learn to modify its input rather than recreate everything from scratch
Layer normalization normalizes activations across the feature dimension for each token:
- Stabilizes training by keeping activation magnitudes consistent
- Applied after adding the residual:
- Unlike batch norm, works well with variable sequence lengths
Positional Encoding
Since attention has no inherent notion of sequence order (it's permutation-invariant), we must inject positional information:
- Sinusoidal encodings: fixed patterns using sine/cosine at different frequencies
- Learned embeddings: trainable position vectors
- Added to input embeddings before the first layer