Activation Functions
Overview of common activation functions with their mathematical equations, derivatives, and Python implementations.
Sigmoid
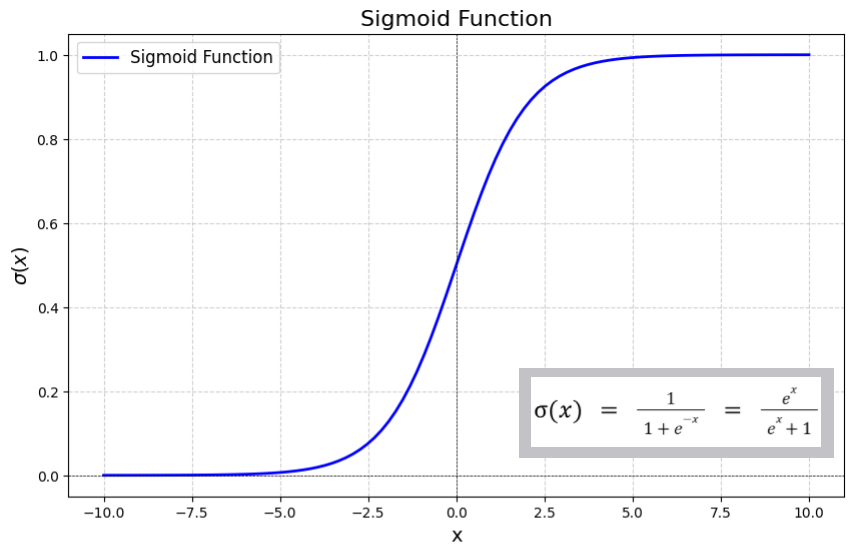 Image Credits: https://www.geeksforgeeks.org/machine-learning/derivative-of-the-sigmoid-function/
Image Credits: https://www.geeksforgeeks.org/machine-learning/derivative-of-the-sigmoid-function/
- Mathematical function that maps any real-valued number into a value between 0 and 1
- Non-linear activation function that improves model performance as it gains the ability to handle non-linearity
Equation:
Derivative:
import math
def sigmoid(z: float) -> float:
result = 1 / (1 + math.exp(-1 * z))
return round(result, 4)Softmax
- Mathematical function that converts a vector of real-valued scores into a probability distribution
- Generalization of sigmoid to multiple classes, ensuring all outputs sum to 1
- Non-linear activation function commonly used in the output layer for multi-class classification
Equation:
Derivative:
For the softmax function, the partial derivative with respect to element is:
When :
When :
import math
import numpy as np
def softmax(scores: list[float]) -> list[float]:
scores_np = np.array(scores)
probabilities = np.exp(scores_np) / np.sum(np.exp(scores_np))
return probabilities.tolist()ReLU (Rectified Linear Unit)
- Simple activation function that outputs the input directly if it is positive, otherwise outputs zero
- Addresses the vanishing gradient problem common in sigmoid and tanh functions
- Computationally efficient and helps with sparse activations in deep networks
Equation:
Derivative:
When :
When :
def relu(x: float) -> float:
return max(0.0, x)Leaky ReLU
- Variant of ReLU that allows a small, non-zero gradient when the input is negative
- Addresses the "dying ReLU" problem where neurons can become inactive and stop learning
- Uses a small positive slope (typically 0.01) for negative inputs instead of zero
- Non-linear activation function that maintains gradient flow even for negative inputs
Equation:
where is a small positive constant (typically 0.01).
Derivative:
When :
When :
def leaky_relu(x: float, alpha: float = 0.01) -> float:
return max(alpha * x, x)