An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
Vision Transformer (ViT) replaces convolutions with a pure Transformer encoder over image patches, using a learnable [class] token and minimal inductive bias to achieve strong image recognition performance at scale.
Paper Link
Key ideas
- Vision Transformer (ViT): Replaces convolutional layers with a pure Transformer encoder that processes images as sequences of patches, achieving strong image recognition performance at scale
- Patch-based Processing: Images are divided into fixed-size patches (e.g., 16×16 pixels), flattened, and linearly projected into vectors that serve as "tokens" for the Transformer
- Minimal Inductive Bias: Unlike CNNs with built-in locality and translation equivariance, ViTs learn these properties from data through self-attention and MLP layers
- Learnable [class] Token: A special token prepended to the patch sequence aggregates global image information for classification
- Position Embeddings: Added to patch embeddings to preserve spatial relationships, enabling the permutation-invariant Transformer to understand image structure
Key Definitions
| Term | Definition |
|---|---|
| Inductive Bias | - Assumptions a learning algorithm makes to predict outputs given inputs it hasn’t encountered before. - Vision Transformers (ViT) have significantly less image-specific inductive bias compared to Convolutional Neural Networks (CNNs). - In CNNs, inductive biases include locality (considering only nearby pixel relationships), two-dimensional neighborhood structure, and translation equivariance (the ability to recognize objects regardless of their position in the image), which are inherently integrated into each layer throughout the model. - In contrast, in ViT, only the Multi-Layer Perceptron (MLP) layers exhibit locality and translation equivariance, while the self-attention layers operate globally. |
| Translation Equivariance | - Property of a system where translating the input (e.g., shifting an image to the left or right) results in an equivalent translation of the output. - CNNs naturally possess translation equivariance, meaning they can recognize objects regardless of their position in an image. This property is embedded within the convolution operations of CNNs. - In Vision Transformers, this is not inherently present in the self-attention mechanism, and such properties must be learned from the data during training. |
| Locality | - Locality refers to focusing on local features or small regions of the input data, which is a characteristic behavior of convolutional layers in CNNs. - In Vision Transformers, locality is not inherently enforced in the self-attention layers as it is in CNNs. - CNNs process local neighborhoods of pixels at each layer, while Vision Transformers process the entire image at once, making their self-attention global rather than local. - Locality can be introduced in ViTs through MLP layers which operate locally and are translationally equivariant. - This shift from local to global processing is one of the main differences in how these two architectures handle image data. |
| Patches | - Instead of processing an entire image as a whole, the ViT model divides the image into fixed-size patches. Each patch is treated similarly to a token in NLP. - An image of size (height, width, channels) is split into a grid of patches, each of size . This results in patches. - Each patch is flattened and linearly projected into a vector of a fixed dimension, referred to as the patch embedding. - This linear projection maps the pixels of each patch to a -dimensional vector, where is the latent vector size of the Transformer. |
| Position Embeddings | - Since the Transformer model is permutation-invariant and does not inherently encode the spatial structure of the input, position embeddings are added to provide information about the positions of patches within the original image. - Learnable position embeddings are added to the patch embeddings. These position embeddings are vectors that are learned during training and are added to the patch embeddings to retain information about the patch’s position in the original image. - The standard implementation uses 1D learnable position embeddings, which are added to the sequence of patch embeddings. |
| Extra Learnable Embeddings: [class] token | - Similar to the [CLS] token in BERT for NLP, an additional learnable embedding, referred to as the “classification token” ([class] token), is prepended to the sequence of patch embeddings. - The state of this [class] token at the output of the Transformer encoder serves as the final image representation. - During pre-training and fine-tuning, a classification head (typically an MLP with one hidden layer) is attached to this [class] token for predicting the class of the image. |
| Classification Head | - A head attached to the Transformer encoder’s output that converts the representation into a class prediction. - During the pre-training phase, it is usually an MLP with one hidden layer to allow the model to learn more complex representations. - During fine-tuning, it is often replaced by a linear layer to reduce computational complexity and speed up training, as the model has already learned a rich set of features. |
Here is a tiny patching toy to make the patch/token idea concrete:
Patch embedding toy
A tiny 64×64 image gets split into square patches, which become tokens for the Transformer.
Each patch (a small P×P×C block of pixels) includes the color channels along the
depth dimension; the toy above only draws the 2D layout, but the C channels are
part of the flattened vector. A linear projection maps each P×P×C patch to a
fixed D-dimensional patch embedding (D does not change with P), then position
embeddings are added and a learnable [class] token is prepended so the
Transformer can summarize the whole image for classification.
Model Architecture
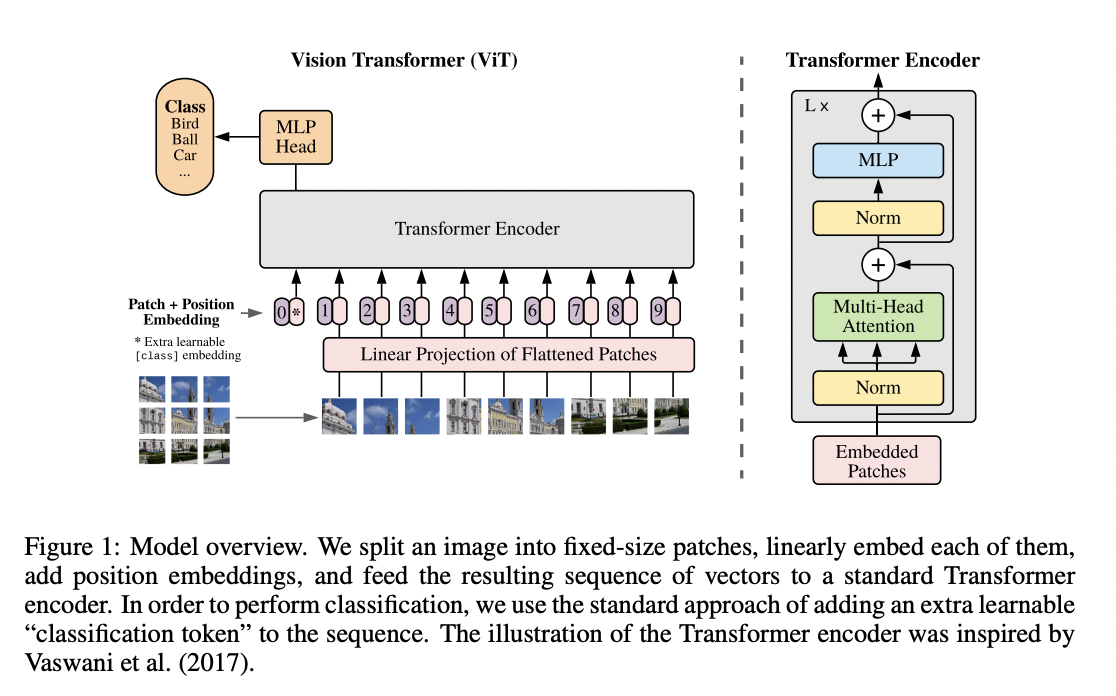
Figure: ViT splits an image into fixed-size patches, embeds them with position info, and feeds them through a Transformer encoder; a learnable class token is used for classification.
-
Input Processing
- Split the input image into fixed-size patches.
- Flatten and linearly project each patch to create patch embeddings.
- Aligns all patch tokens into a consistent, learnable format that the transformer encoder expects.
- Add learnable position embeddings to the patch embeddings.
- Prepend the
[class]token to the sequence of patch embeddings.- Acts as a global placeholder to aggregate information from the entire image for classification (similar to BERT's
[CLS])
- Acts as a global placeholder to aggregate information from the entire image for classification (similar to BERT's
-
Transformer Encoder
- Feed the sequence of patch embeddings (with position embeddings added and the
[class]token prepended) into a standard Transformer encoder. - Use alternating layers of multi-headed self-attention and MLP blocks.
- Different attention heads look at different aspects of the relationships between patches.
- Apply Layer Normalization (LN) before every block and residual connections after every block.
- Take the output corresponding to the
[class]token from the final encoder layer as the image representation for classification.
- Feed the sequence of patch embeddings (with position embeddings added and the
-
Classification Head
- Attach a classification head to the final
[class]token representation. - Use an MLP with one hidden layer during pre-training.
- Use a single linear layer during fine-tuning.
- Produce the final class probabilities or logits from this head.
- Attach a classification head to the final
Challenges
- Application to Other Vision Tasks:
- While the ViT has shown promise in image classification, extending its application to other computer vision tasks such as object detection and segmentation remains a challenge. This indicates the need for further research and development to adapt the ViT architecture to these tasks effectively.
- Self-Supervised Pre-Training:
- The initial experiments with self-supervised pre-training (e.g., masked patch prediction) show potential, but there is still a significant gap between the performance of self-supervised and large-scale supervised pre-training. Bridging this gap is crucial for making self-supervised learning more effective and practical.
- Scaling ViT:
- Further scaling of the Vision Transformer could lead to improved performance. However, this comes with challenges related to computational resources and efficiency. Ensuring that the model can be scaled effectively without prohibitive computational costs is a critical area of focus.
Notes
| Feature | Convolutional Neural Networks (CNNs) | Vision Transformers (ViTs) |
|---|---|---|
| Architecture | Uses Convolution + Pooling Layers | Uses Transformer Encoder with Self-Attention |
| Receptive Field | Local receptive field but expands with depth | Global from the start |
| Positional Awareness | Implicit through structure | Explicit through positional encodings |
| Data Requirements | Quite effective with smaller datasets | Requires large-scale datasets |
| Inductive Bias | Strong | Minimal but more flexible |
| Parallelism Potential | Moderate | Very High |
| Model Scaling | Less scalable to large models | Highly scalable |
| Interpretability | Through pooling layers but still difficult | Can be enhanced with attention visualization but also quite difficult |
Table adapted from: DataCamp Vision Transformers Tutorial
Code
# Minimal ViT-like patch embedding + class token in PyTorch
import torch
import torch.nn as nn
class PatchEmbed(nn.Module):
def __init__(self, img_size=224, patch_size=16, in_chans=3, embed_dim=768): # P=16, D=768
super().__init__()
self.proj = nn.Conv2d(
in_chans, embed_dim, kernel_size=patch_size, stride=patch_size # P×P stride
)
num_patches = (img_size // patch_size) ** 2 # total patches N
self.cls_token = nn.Parameter(torch.zeros(1, 1, embed_dim)) # learnable [class]
self.pos_embed = nn.Parameter(torch.zeros(1, 1 + num_patches, embed_dim)) # pos emb
def forward(self, x): # x: [B, C, H, W]
x = self.proj(x) # patchify + linear projection -> [B, D, H/P, W/P]
x = x.flatten(2).transpose(1, 2) # flatten grid -> [B, N, D]
cls = self.cls_token.expand(x.size(0), -1, -1) # copy class token per batch
x = torch.cat([cls, x], dim=1) # prepend class token -> [B, 1+N, D]
return x + self.pos_embed # add position embeddings
embed = PatchEmbed(img_size=224, patch_size=16, in_chans=3, embed_dim=768)
tokens = embed(torch.randn(2, 3, 224, 224)) # batch of 2 images
print(tokens.shape) # -> [2, 197, 768]