Deep Neural Networks for YouTube Recommendations
YouTube's deep neural network-based recommendation system using a two-stage architecture with candidate generation and ranking, incorporating negative sampling, importance weighting, and features like watch history and search queries to provide personalized video recommendations.
Paper Link
Key Definitions
| Term | Definition |
|---|---|
| Negative Sampling (Section 3.1) | - This is a technique where instead of considering all videos as potential "negative" examples (videos not watched by the user), the model samples a small subset of videos from the millions available - These sampled videos serve as negative examples for training - Instead of considering every possible video in the entire YouTube library as a negative example, the model samples a smaller, manageable number of videos from the background distribution (which represents the overall distribution of videos). |
| Importance Weighting (Section 3.1) | - Importance weighting is a statistical technique that assigns weights to the sampled negative examples based on how representative they are of the full distribution of possible negative videos. - This ensures that the model doesn't get skewed by over-representing certain types of videos in the negative samples. - The weights help adjust the impact of these sampled negatives during training so that the final model accurately reflects the full range of videos that a user might encounter. |
| Bootstrapping (Section 3.3) | - In machine learning and systems like YouTube's recommendation engine, bootstrapping means helping a process get started and gain momentum - In this case, it means the recommendation system plays an active role in helping a video gain initial traction by recommending it to users, based on signals that suggest it could become popular (e.g., high engagement in a short time, rapid increases in views, or social sharing). |
System Overview
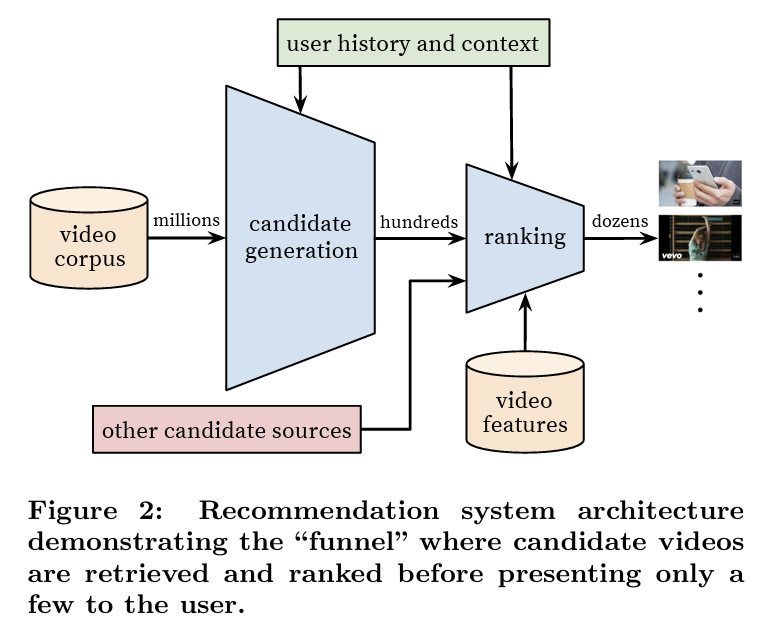
Two-Stage Recommendation Architecture
- The recommendation system is divided into two stages: candidate generation and ranking.
- This two-stage approach helps in efficiently managing a vast corpus of millions of videos while still providing personalized recommendations.
- The candidate generation stage retrieves a small subset (hundreds) of potentially relevant videos based on user history.
- The ranking stage further narrows down these candidates by assigning scores to each video, allowing only the most relevant videos to be shown to the user.
Candidate Generation
- Evolution from Matrix Factorization
- The system evolved from a traditional matrix factorization approach (used in earlier recommendation systems) to deep neural networks, offering more complex and non-linear modeling capabilities.
- The approach is described as a non-linear generalization of matrix factorization, making the system more effective in retrieving relevant candidates
- Recommendation as a Multiclass Classification Problem
- Here, the system predicts which specific video a user will watch next from among millions of possible videos, based on user context and history.
- The classification problem is modeled with a softmax classifier, where the deep neural network learns high-dimensional embeddings for both users and videos.
- The model is trained on implicit feedback (e.g. video watches) rather than explicit feedback (e.g. ratings)
- This allows the system to learn from the vast amounts of user history available, even in the absence of explicit preferences or ratings
- Positive examples are derived from completed video watches while negative examples are based on videos that were not watched\
- As there are millions of video classes which causes computational complexity, the system uses negative sampling which accelerates the training process by focusing the model on a subset of the corpus
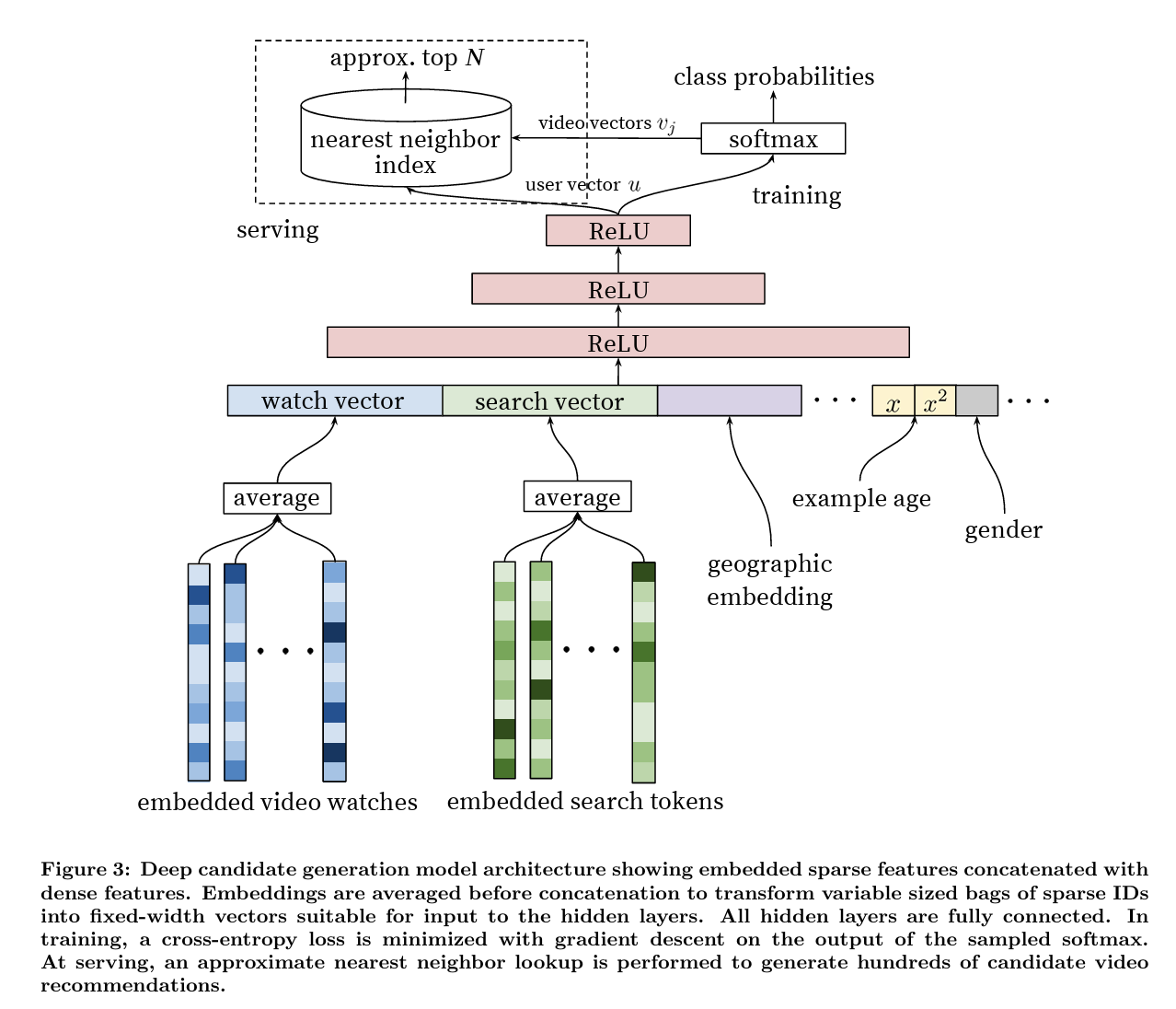
-
User watch history and embedding generation
- Each user's watch history is represented as a sequence of sparse video IDs, which is mapped into dense embedding vectors using a neural network
- These embeddings are learned by the system and updated as the model trains
-
Feedforward Neural Networks
- The embeddings are fed into the neural network's input layer, which consists of a wide concatenation of features
- Network is composed of several layers of fully connected ReLU, to add non-linearity
-
Variable Length input
- A challenge for the model is that users have different lengths of watch history (e.g. some only watch a few while others watch hundreds)
- As the network requires fixed-size dense inputs, the system averages the embeddings of watched videos to transform the variable length sequence into a fixed width
-
Joint learning of embeddings
- A key advantage of this approach is that the video embeddings are learned jointly with the other model parameters. This means that the embeddings are not precomputed but are instead optimized as part of the model’s training process.
- As a result, the system is able to continuously refine the embeddings based on both the user's behavior and the content of the videos, making them more accurate and representative of user preferences.
-
In addition to watch history, the system incorporates other non-video features to improve the quality of recommendations
- Search history: Tokenized and embedded similarly to watch history. Each search query is broken down into unigrams and bigrams, and then embedded into a dense vector representation.
- Demographic information: : Features like the user's geographic region and device type are also embedded and concatenated with the other inputs. Simple binary and continuous features, such as gender, age, and logged-in state, are normalized to a [0, 1] range and input directly into the network.
-
A particularly important feature for YouTube's recommendation system is the "example age" feature, which captures the freshness of videos.
- Since new videos are uploaded to YouTube every second, the recommendation system must be able to identify and promote fresh content.
- The "example age" feature represents the time since a video was uploaded and is critical for ensuring that the model does not become biased towards older content.
- At serving time, the example age is set to zero or slightly negative to reflect that the model is making predictions at the end of the training window, ensuring prioritization of most recent content
- This feature also plays a key role in identifying and promoting viral content, which tend to gain popularity quickly and must be recommended to users while they are still relevant (bootstrap viral content)
-
Recommendation systems often rely on surrogate learning problems, which are simpler problems that approximate the real task of interest
- The system does not directly train on user satisfaction (which is difficult to measure) but instead focuses on more measurable outcomes like whether a user completes watching a video
- The authors emphasize that choosing the right surrogate problem can make or break the success of a recommendation system
-
Another key challenge is to ensure that the system weights users equally during training, else a small group of highly active users could dominate the training process and skew the recommendations
- The authors introduce a strategy to generate a fixed number of training examples per user
-
It is also emphasized the importance of withholding certain information from the model during training toe avoid overfitting on the surrogate problem
- For example, if the system knows that a user has just searched for "Taylor Swift," the most likely video they will watch next is a Taylor Swift video. If the model is allowed to exploit this information during training, it could simply reproduce the user’s search results as recommendations.
- To prevent this, the system discards sequence information from search queries and instead represents them as unordered bags of tokens.
- This helps the model generalize better and avoids simply recommending videos that appeared on the user’s most recent search results page.
-
The paper also discusses asymmetric consumption patterns, which are common in content platforms like YouTube
- These patterns occur when users consume content in a sequential manner (e.g., watching episodes of a TV series in order)
- To model this behavior, the authors introduce the idea of rolling back a user's history during training.
- Instead of randomly holding out one watch from the user’s history (which is common in collaborative filtering systems), the model only uses actions the user took before the held-out video to predict future behavior.
- This method ensures that the model learns from a user’s natural consumption sequence, improving its ability to predict what the user will watch next.
Ranking
- In the ranking phase, the goal is to assign a score to each video candidate to determine which ones should be recommended to the user.
- Objective Function: Watch Time vs. Click-Through Rate
- In many recommendation systems, the objective is often click-through rate (CTR), which measures how likely a user is to click on a video.
- However, optimizing solely for CTR can lead to suboptimal outcomes because it encourages clickbait
- To address this, YouTube’s ranking model optimizes for expected watch time per impression rather than just CTR, accounting for watch time
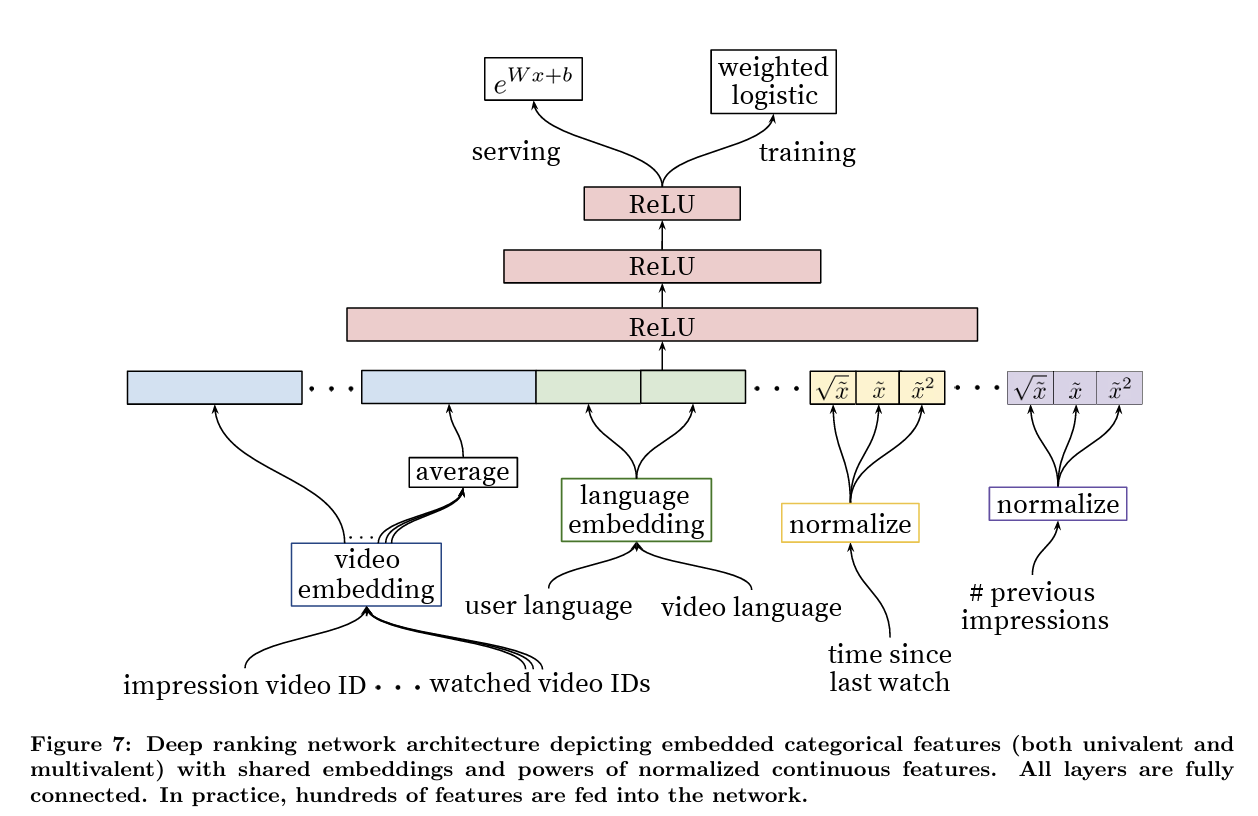
- In the ranking phase, the system has access to many more features than in candidate generation: user, video and impression-level features
- One important technique used in the model is shared embeddings
- Different features that represent the same type of entity (e.g., video IDs from various parts of the user’s history) share the same underlying embedding space
- Another key aspect of the ranking model is ensuring churn in recommendations, which means that the system does not show the same set of videos repeatedly to the user
- Continuous features, such as the number of previous impressions of a particular video, help the system adjust recommendations so that users are not repeatedly shown videos they’ve already ignored
- One important technique used in the model is shared embeddings
- The ranking model is trained using logistic regression, with modifications to account for the focus on watch time
- Specifically, weighted logistic regression is used to prioritize positive impressions based on the amount of time a user spends watching the video
- For positive impressions (i.e., when the video was clicked and watched), the watch time is used as a weight in the logistic regression mode. This ensures the model focuses more on recommendations that lead to longer watch times
- For negative impressions (i.e., when the video is shown but not clicked), the weight is set to a default value (typically 1)
- The exponential function is applied to the raw output of the model, converting it into a positive number that represents the expected watch time for a given video impression
Code
import numpy as np
def sample_negatives(num_items, positives, k=50, rng=None):
rng = np.random.default_rng(rng)
negatives = []
while len(negatives) < k:
cand = rng.integers(0, num_items)
if cand not in positives:
negatives.append(cand)
return negatives
def softmax_logits(logits):
# Stabilize before exponentiation to avoid overflow.
logits = logits - np.max(logits)
exp = np.exp(logits)
return exp / np.sum(exp)
def average_embeddings(embedding_table, ids):
if not ids:
# Cold-start / no-history case.
return np.zeros(embedding_table.shape[1])
return np.mean(embedding_table[ids], axis=0)
def relu(x):
return np.maximum(0, x)
def mlp_forward(x, weights, biases):
# Simple MLP with ReLU on hidden layers, linear output.
for w, b in zip(weights[:-1], biases[:-1]):
x = relu(w @ x + b)
return weights[-1] @ x + biases[-1]
# Candidate Generation (implicit feedback + negative sampling)
def candidate_generation_step(
user_hist_ids,
user_feat_vec,
video_emb,
video_bias,
user_mlp_w,
user_mlp_b,
num_items,
):
# Aggregate watched items into a fixed-size user representation.
user_hist_emb = average_embeddings(video_emb, user_hist_ids)
# Concatenate learned embeddings with hand-crafted/user features.
x = np.concatenate([user_hist_emb, user_feat_vec])
# Deep user tower (ReLU MLP) to produce a user embedding.
user_vec = mlp_forward(x, user_mlp_w, user_mlp_b)
# One logit per candidate item (dot with item embeddings).
logits = video_emb @ user_vec + video_bias
# Use the last watch as the positive; sample a small batch of negatives.
positives = set(user_hist_ids[-1:]) # last watched as positive
negatives = sample_negatives(num_items, positives, k=50)
sampled = list(positives) + negatives
# Softmax only over sampled set (approximate full softmax).
sampled_logits = logits[sampled]
sampled_probs = softmax_logits(sampled_logits)
return sampled, sampled_probs
# Ranking (expected watch time via weighted logistic regression)
def ranking_score(user_vec, video_vec, feat_vec, rank_mlp_w, rank_mlp_b):
# Combine user, item, and impression-level features for final scoring.
x = np.concatenate([user_vec, video_vec, feat_vec])
# ReLU MLP to model non-linear feature interactions.
raw = mlp_forward(x, rank_mlp_w, rank_mlp_b)
return np.exp(raw) # expected watch time proxy
# Example usage
num_items = 1_000_000
embed_dim = 64
hidden_dim = 128
video_emb = np.random.normal(size=(num_items, embed_dim))
video_bias = np.random.normal(size=(num_items,))
user_feat_vec = np.random.normal(size=(16,))
user_hist_ids = [10, 91, 1234, 5002]
user_mlp_w = [
np.random.normal(size=(hidden_dim, embed_dim + 16)),
np.random.normal(size=(embed_dim, hidden_dim)),
]
user_mlp_b = [
np.random.normal(size=(hidden_dim,)),
np.random.normal(size=(embed_dim,)),
]
sampled_ids, sampled_probs = candidate_generation_step(
user_hist_ids,
user_feat_vec,
video_emb,
video_bias,
user_mlp_w,
user_mlp_b,
num_items,
)
user_vec = average_embeddings(video_emb, user_hist_ids)
video_vec = video_emb[sampled_ids[0]]
feat_vec = np.random.normal(size=(12,))
rank_mlp_w = [
np.random.normal(size=(hidden_dim, embed_dim + embed_dim + 12)),
np.random.normal(size=(1, hidden_dim)),
]
rank_mlp_b = [
np.random.normal(size=(hidden_dim,)),
np.random.normal(size=(1,)),
]
score = ranking_score(user_vec, video_vec, feat_vec, rank_mlp_w, rank_mlp_b)