LoRA: Low-Rank Adaptation of Large Language Models
LoRA (Low-Rank Adaptation) enables parameter-efficient fine-tuning of large language models by decomposing weight updates into low-rank matrices, dramatically reducing trainable parameters while preserving pre-trained knowledge and allowing zero-inference-latency deployment through weight merging.
Paper Link
Key Definitions
| Term | Definition |
|---|---|
| Inference Latency | - Refers to the amount of time it takes for a model to generate predictions after receiving input - The document discusses inference latency in relation to adapter layers, which are used in neural network architectures to adapt pre-trained models for new tasks with minimal re-training of the model - It mentions that these layers, while beneficial for parameter efficiency, can introduce significant latency during the inference phase, especially in online scenarios where the batch size is small |
| Intrinsic Dimension | - Refers to the underlying complexity or the minimum number of parameters required to capture the significant variance or behavior of a model - In the context of neural networks, especially those pre-trained on a vast amount of data like GPT-3, the intrinsic dimension indicates how the effective information or the actual degrees of freedom within the model can be represented with fewer parameters than those used in the full model - Essentially, it's about understanding the minimal complexity necessary to achieve comparable performance |
| Adapter Layers | - In the context of neural network architectures, particularly those involving transfer learning, an adapter layer is a small module inserted between the pre-existing layers of a pre-trained model to fine-tune the model for specific tasks without altering the original parameters significantly - These adapter layers allow for task-specific training with minimal impact on the overall parameter count of the model, providing an efficient way to customize large models for new tasks |
| Prefix-Tuning | - In prefix-tuning, a set of trainable vectors, known as a "prefix", is prepended to the sequence of embeddings at the input of each Transformer layer - These prefixes serve as additional, task-specific parameters that influence the behavior of the model during the forward pass - Unlike traditional fine-tuning, which updates all model weights, prefix-tuning adapts the model by only learning the prefixes - This allows the base model to retain its general capabilities while gaining the ability to perform well on specific tasks |
| Low-Rank Property | - In the context of neural networks, the low-rank property refers to the ability of the network's weights or transformations to be approximated or fully captured using matrices with a rank significantly lower than the dimensions of the matrices themselves - This suggests that the essential information in these large matrices can be condensed into a much smaller subspace - The low-rank property is particularly relevant for model adaptation because it implies that small, targeted changes (using low-rank matrices) can effectively capture the necessary adjustments for new tasks without needing to alter the entire high-dimensional weight matrices of a pre-trained model |
Motivation
- Challenges with Large Models: As language models like GPT-3 have grown larger, full fine-tuning (retraining all model parameters) has become increasingly impractical due to high computational and storage demands
- Need for Efficiency: There is a critical need for more efficient methods to adapt these large pre-trained models to new tasks without the overhead of retraining all parameters
Introduction to LoRA
- LoRA addresses these challenges by introducing a method to adapt models using low-rank matrices
- his method significantly reduces the number of trainable parameters by freezing the original pre-trained model weights and only training small rank decomposition matrices (A and B) that modify the model's behavior
Advantages
- Parameter Efficiency: By using low-rank matrices, LoRA limits the number of parameters that need to be updated, making the adaptation process more manageable and less resource-intensive
- Preservation of Pre-trained Knowledge: The approach preserves the underlying structure and knowledge of the pre-trained model, leveraging the extensive learning it has already undergone
- Flexibility and Scalability: LoRA enables quick adaptation to multiple tasks by swapping out the low-rank matrices tailored for each task, facilitating faster deployment and easier scaling
LoRA Example
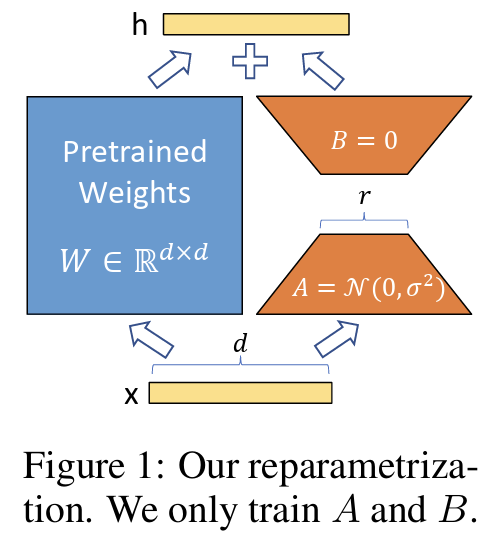
Instead of computing the full weight update matrix during fine-tuning, LoRA introduces a more efficient approach based on the insight that these updates have a low intrinsic rank.
Consider a pre-trained weight matrix . During traditional fine-tuning, we would learn a full update matrix and update the weights as:
For large models like GPT-3 with 7B parameters, this means computing and storing an equally massive 7B-parameter update matrix, which is computationally expensive and memory-intensive.
How LoRA Works
LoRA solves this problem by decomposing the weight update matrix into two smaller, low-rank matrices:
where:
- is a low-rank matrix (typically initialized with random Gaussian values)
- is a low-rank matrix (typically initialized with zeros)
- is the rank, which is much smaller than the original dimensions
The updated forward pass becomes:
Key Benefits of This Decomposition:
- Dramatic Parameter Reduction: Instead of training parameters, we only train parameters. For example, if and , we reduce from 1,000,000 parameters to just 4,000 parameters
- Frozen Base Model: The original weights remain frozen during training, preserving the pre-trained knowledge
- Task Switching: Different tasks can use different and matrices while sharing the same base model, enabling efficient multi-task deployment
- No Inference Latency: Unlike adapter layers, LoRA can be merged into the original weights () after training, adding zero additional inference cost
LoRA Hyperparameters: Rank and Alpha
LoRA introduces two critical hyperparameters that control the adaptation process: the rank and the scaling factor .
Rank ()
The rank determines the dimensionality of the low-rank decomposition and directly controls the expressiveness versus efficiency trade-off:
- Definition: is the inner dimension of the matrices and , representing the bottleneck size of the adaptation
- Impact on Parameters: The number of trainable parameters is , so lower ranks mean fewer parameters to train
- Typical Values: Common choices range from to , with or being popular defaults
- Trade-offs:
- Lower rank (): Maximum parameter efficiency, faster training, but may limit the model's ability to capture complex task-specific patterns
- Higher rank (): Greater expressiveness and better performance on complex tasks, but with increased parameter count and training cost
Empirical studies in the original paper show that surprisingly low ranks (even or ) can achieve competitive performance on many tasks, validating the low intrinsic dimension hypothesis.
Alpha ()
The scaling factor controls the magnitude of the LoRA adaptation relative to the pre-trained weights:
- Definition: is a constant used to scale the LoRA contribution, typically applied as:
- Purpose: Acts as a learning rate modifier specifically for the LoRA parameters, allowing control over how much the adaptation influences the model
- Typical Values: Often set to values like or , though this varies by application
- Scaling Relationship: The factor normalizes the contribution of LoRA updates, making the magnitude somewhat independent of the choice of rank
Practical Considerations
Choosing Rank and Alpha:
- Start with a moderate rank like and as baseline values
- For simple tasks (e.g., sentiment classification), lower ranks may suffice
- For complex tasks (e.g., instruction following, domain-specific reasoning), higher ranks may be necessary
- The ratio can be kept constant when experimenting with different ranks to maintain consistent update magnitudes
Independence from Task Complexity: Interestingly, research shows that the optimal rank doesn't always correlate with task difficulty. Some complex tasks can be effectively learned with very low-rank adaptations, suggesting that the required weight changes often lie in low-dimensional subspaces regardless of task complexity.
Applying LoRA (Hugging Face PEFT)
Below is a minimal example showing how to attach LoRA adapters to a causal LM, train only the low-rank parameters, and save the adapter weights.
from transformers import AutoModelForCausalLM, AutoTokenizer, TrainingArguments, Trainer
from peft import LoraConfig, TaskType, get_peft_model
model_id = "gpt2"
tokenizer = AutoTokenizer.from_pretrained(model_id)
base_model = AutoModelForCausalLM.from_pretrained(model_id)
# Configure LoRA to target attention projection layers
lora_config = LoraConfig(
task_type=TaskType.CAUSAL_LM,
r=8,
lora_alpha=16,
lora_dropout=0.05,
target_modules=["c_attn"]
)
model = get_peft_model(base_model, lora_config)
# Example data
texts = ["LoRA makes fine-tuning efficient.", "Low-rank adapters scale well."]
encodings = tokenizer(texts, return_tensors="pt", padding=True)
args = TrainingArguments(
output_dir="lora-demo",
per_device_train_batch_size=2,
num_train_epochs=1,
learning_rate=2e-4,
logging_steps=1,
)
trainer = Trainer(
model=model,
args=args,
train_dataset=[encodings] * 10,
)
trainer.train()
model.save_pretrained("lora-demo-adapter")