DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
DeepSeekMath introduces a 7B parameter model that achieves state-of-the-art mathematical reasoning by continuing pre-training on 120B math-related tokens from Common Crawl and introducing Group Relative Policy Optimization (GRPO)
Paper Link
Key Definitions
| Term | Definition |
|---|---|
| Chain-of-Thought (CoT) Prompting | - A prompting technique where the model is encouraged to show its step-by-step reasoning process when solving problems, rather than directly producing an answer - This helps improve performance on complex reasoning tasks by decomposing the solution into intermediate reasoning steps |
| Program-of-Thought (PoT) | - A problem-solving approach where the model generates a Python program to solve mathematical problems, often leveraging libraries like sympy and math for intricate computations- The generated program is then executed to obtain the final answer, improving reliability on symbolic and numeric tasks |
| Proximal Policy Optimization (PPO) | - An actor-critic reinforcement learning algorithm widely used for fine-tuning large language models - It trains both a policy model (actor) and a value function (critic) and uses a clipped objective to stabilize updates while optimizing behavior through reward signals |
| Rejection Sampling Fine-Tuning (RFT) | - A fine-tuning method where the model generates multiple candidate outputs for each input prompt or question - Only the candidates that produce correct or high-quality answers (according to some verifier or metric) are selected and used for further training, biasing the model toward better responses |
| Common Crawl | - A publicly available repository of web crawl data containing billions of web pages across multiple languages - It serves as a rich source for extracting large-scale, domain-diverse training data for pretraining and continued training of language models |
| fastText | - A lightweight library developed by Facebook AI Research for efficient text classification and representation learning - It learns vector representations of words and can quickly classify text by training on character n-grams, making it particularly useful for large-scale text filtering tasks and handling out-of-vocabulary words |
Introduction
- Mathematical reasoning remains one of the most challenging tasks for large language models due to its complex, structured, and multi-step nature
- Current state-of-the-art challenges
- Data Quality: Existing mathematical corpora are limited in size and diversity
- Training Efficiency: Traditional reinforcement learning methods like PPO require substantial computational resources due to the need for a separate critic model
DeepSeekMath Contributions
- DeepSeekMath Corpus: A meticulously curated dataset of 120B mathematical tokens extracted from Common Crawl through an iterative fastText-based classification pipeline
- Group Relative Policy Optimization (GRPO): A memory-efficient variant of PPO that eliminates the need for a critic model while maintaining effectiveness
The resulting DeepSeekMath 7B model achieves performance approaching GPT-4 and SOTA results among all open-source models
Building the DeepSeekMath Corpus
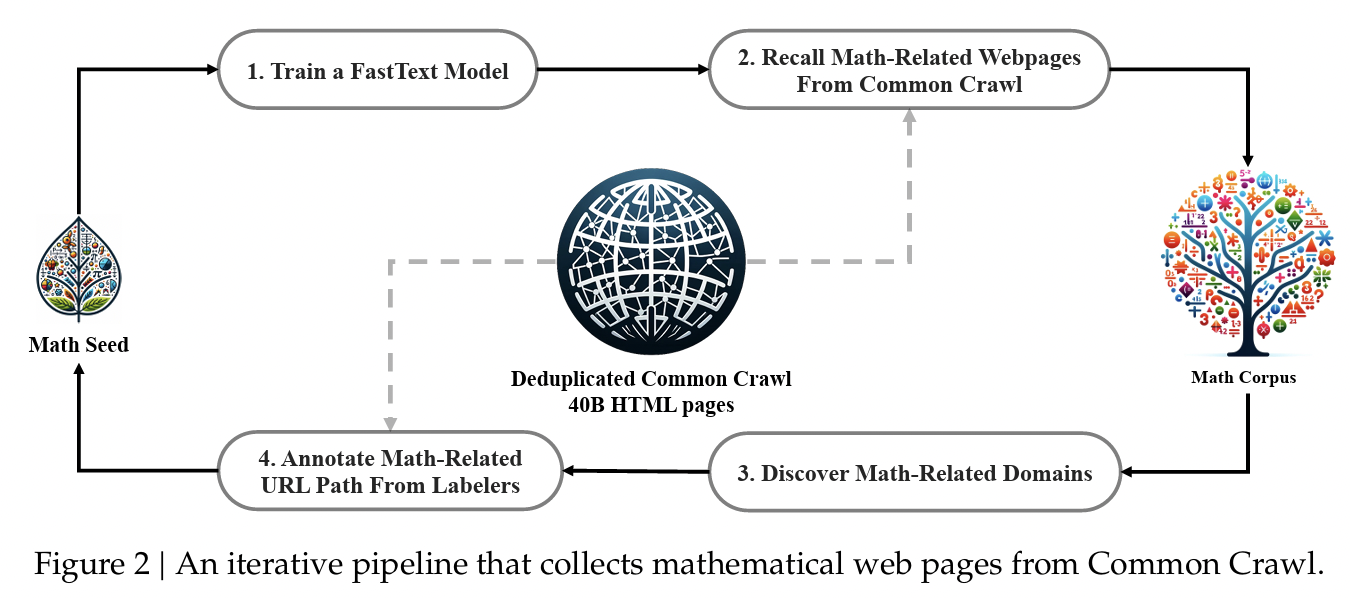
Step 1: Initial Seed Corpus
- Started with OpenWebMath (13.6B tokens), a collection of high-quality mathematical web texts
- Used as positive examples for training a fastText classifier
Step 2: Train FastText Classifier
- Positive examples: 500,000 data points from OpenWebMath
- Negative examples: 500,000 random web pages from Common Crawl
Step 3: Recall Mathematical Web Pages
- Applied the classifier to deduplicated Common Crawl (40B HTML pages)
- Ranked pages by fastText scores
- Preserved only top-ranking pages
Step 4: Domain Discovery and Manual Annotation
- Organized Common Crawl into domains (web pages with same base URL)
- Identified math-related domains (e.g., mathoverflow.net) where >10% of pages were collected
- Manually annotated URL paths within these domains that contain mathematical content
- Added uncollected pages from annotated URLs to seed corpus
Step 5: Iteration
- Trained improved fastText model with enriched seed corpus
- Repeated process for multiple iterations
Results
After 4 iterations:
- 35.5M mathematical web pages collected
- 120B tokens total
Quality Advantages
- High Quality: Models trained on it outperform those trained on existing corpora (MathPile, OpenWebMath, Proof-Pile-2)
- Multilingual: Primarily English and Chinese, enabling strong performance on both language benchmarks
- Large Scale: Multiple times larger than existing mathematical corpora, enabling longer training without repetition
Decontamination
To prevent benchmark contamination, the corpus underwent strict filtering:
- Removed web pages containing 10-gram exact matches with benchmark questions/answers
- For texts less than 10 grams but >=3 grams, used exact matching to filter contaminated pages
Model Architecture and Training
DeepSeekMath-Base 7B
- Started from DeepSeek-Coder-Base-v1.5 7B (rather than a general language model)
- Code training prior to math training proved beneficial for mathematical reasoning
- Surpasses all open-source base models by >10% on MATH
- Multilingual advantage: significantly better on Chinese benchmarks
Supervised Fine-Tuning: DeepSeekMath-Instruct 7B
- Created a diverse mathematical instruction-tuning dataset with 776K examples including mutiple solution formats such as CoT, PoT and hybrid of both
- Achievements
- Surpasses all open-source 7B-70B models on MATH
- Competitive with 70B models despite being much smaller
- Approaches 60% accuracy on MATH with tool use
Group Relative Policy Optimization (GRPO)
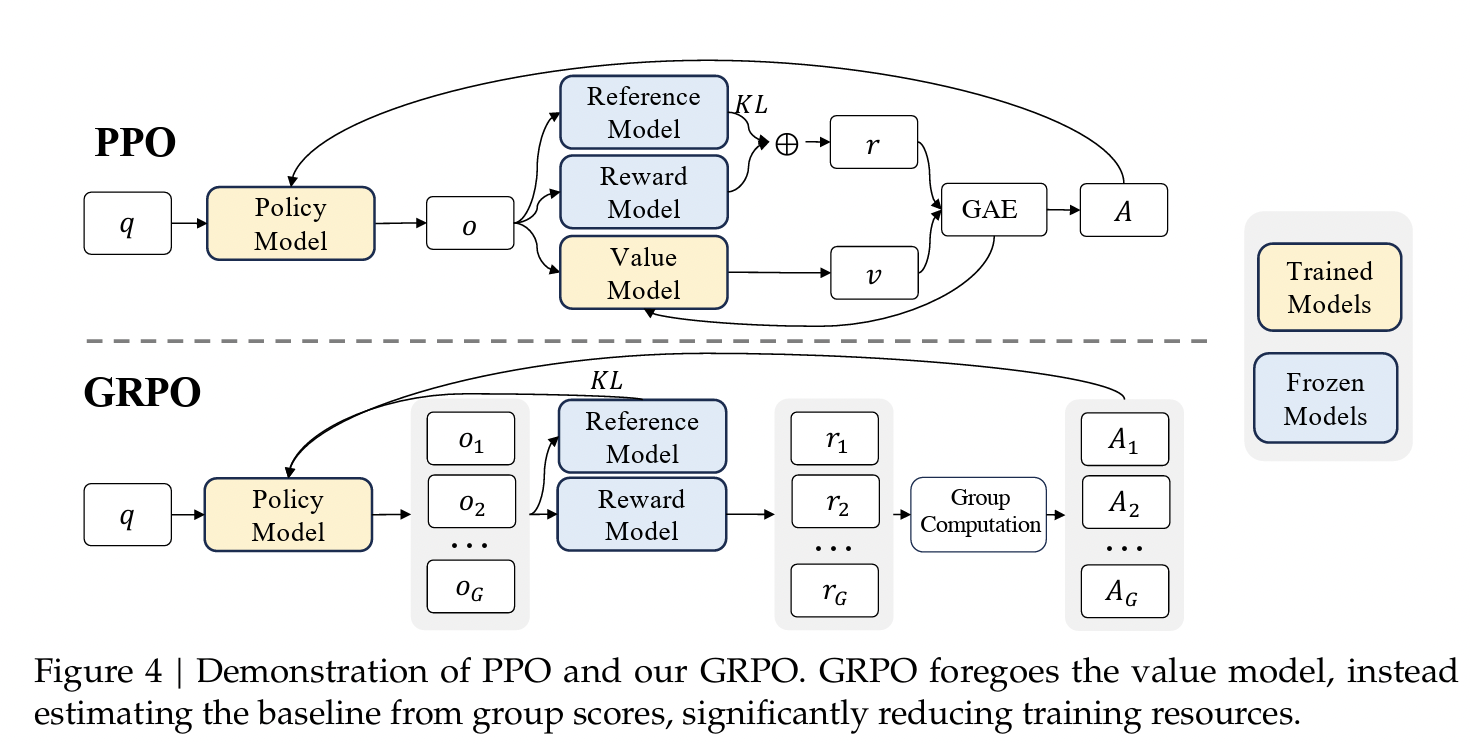
Motivation: The Problem with PPO
Traditional PPO has two main limitations for LLM fine-tuning:
- Memory Overhead: Requires training a separate value function (critic model) of comparable size to the policy model, doubling memory requirements
- Training Complexity: The value function approximation can be challenging when only the final token receives a reward signal
GRPO: A More Efficient Alternative
- GRPO eliminates the critic model and instead uses group statistics as a baseline for advantage estimation.
- For each question, sample multiple outputs (a "group") from the policy model, then use the group's average reward as the baseline instead of a learned value function.
Algorithm
For each training question :
- Sample group of outputs: Generate a group of outputs from the current policy
- Score outputs: Use the reward model to obtain rewards
- Normalize rewards:
- Calculate advantages:
- Outcome supervision: (same for all tokens in output )
- Process supervision: (sum of normalized step rewards from position onward)
- Optimize policy: Maximize the GRPO objective with clipping and KL penalty
GRPO Objective Function
Where:
- : clipping parameter for stability
- : KL penalty coefficient
- : reference model (prevents over-optimization)
Breaking down the components:
-
Outer expectation : Average over all questions and their sampled output groups
-
Group averaging : Average the objective across all outputs in each group
-
Token averaging : Average across all tokens in each output
-
Probability ratio : Measures how much the new policy differs from the old policy for token
- Ratio : New policy assigns higher probability (encouraging this token)
- Ratio : New policy assigns lower probability (discouraging this token)
-
Advantage : The normalized reward signal that determines direction and magnitude of update
- Positive advantage: Reinforce this token (increase probability)
- Negative advantage: Penalize this token (decrease probability)
-
Clipping function : Prevents the policy from changing too drastically in one update
- Limits ratio to range (typically )
- If advantage is positive: clips ratio at to prevent over-optimization
- If advantage is negative: clips ratio at to prevent excessive penalization
-
min operation: Takes the more conservative of the clipped and unclipped objectives
- Ensures stable training by preventing large policy updates
-
KL divergence penalty : Keeps the updated policy close to the reference policy
- controls the strength of this regularization
- Prevents the policy from drifting too far and "forgetting" what it learned during SFT
Intuition: The objective encourages the model to increase probabilities of tokens that led to high rewards (positive advantages) while decreasing probabilities of tokens that led to low rewards (negative advantages), but with safeguards (clipping and KL penalty) to ensure training remains stable.
Demo: GRPO update playground
GRPO update playground
Sample a group of completions, normalize rewards into advantages, and see how clipping and the KL penalty change the update direction.
Use the sliders to see how group normalization and clipping shape updates:
- Increase reward std to amplify advantage magnitudes after normalization
- Push ratio drift or lower epsilon to see more clipping
- Raise KL beta to dampen aggressive policy updates
- Hit Resample group to compare different batches
Code
from datasets import load_dataset
from trl import GRPOTrainer
from trl.rewards import accuracy_reward
dataset = load_dataset("trl-lib/DeepMath-103K", split="train")
trainer = GRPOTrainer(
model="Qwen/Qwen2-0.5B-Instruct",
reward_funcs=accuracy_reward,
train_dataset=dataset,
)
trainer.train()Paper's Key Insights and Findings
- Code Training Benefits Mathematical Reasoning
- Code pre-training significantly improves program-aided mathematical reasoning
- Two-stage training (code → math) is best for reasoning without tools
- Mixed training mitigates catastrophic forgetting and synergizes coding + math abilities
- ArXiv Papers Are Surprisingly Ineffective
- Trained models on arXiv-only corpora (MathPile, ArXiv-RedPajama) show no notable improvements on mathematical benchmarks
- Some cases even showed performance degradation
- Caveat is that this may be more useful at larger model scales (tested on 1.3B and 7B models) and may be effective for other tasks (e.g. theorem informalization)
- RL improves Maj@K but not Pass@K
- Definitions
- Pass@K: Percentage of problems where at least one of K samples is correct (measures raw capability)
- Maj@K: Percentage of problems where majority of K samples are correct (measures output distribution robustness)
- This means that RL does not necessarily improve fundamental capabilities, rather it makes the output distribution more robust and consistent