Generative Adversarial Networks (GAN)
Generative Adversarial Networks (GANs) train two competing neural networks (a generator that creates synthetic samples and a discriminator that distinguishes real from fake) in a minimax game to learn data distributions and generate realistic samples without explicit density modeling.
Paper Link
Key Definitions
| Term | Definition |
|---|---|
| Discriminative models | - Discriminative models are a class of models in machine learning that are used to distinguish between different classes in the data - They work by learning the decision boundary between the classes. - Unlike generative models, which try to model the actual distribution of each class (i.e., how the data is generated), discriminative models focus solely on learning the boundary that separates different classes. |
| Restricted Boltzmann Machines (RBMs) | - Restricted Boltzmann Machines (RBMs) are a type of stochastic neural network that are primarily used for unsupervised learning - RBMs have a two-layer architecture: 1. Visible Layer (v): This layer represents the observed data. Each neuron in this layer corresponds to a feature in the input data. 2. Hidden Layer (h): This layer captures the dependencies between the observed variables. Each neuron in this layer represents a latent feature that helps explain the observed data. |
| Markov Chains | - A Markov chain is a stochastic process that describes a sequence of possible events where the probability of each event depends only on the state attained in the previous event. |
Introduction
- Discriminative models, such as those used for classification, have been highly successful in deep learning applications
- These models learn to map high-dimensional sensory inputs to class labels using algorithms like backpropagation and dropout
- They leverage piecewise linear units that ensure well-behaved gradients, which are crucial for effective training
- Generative models aim to generate new data samples similar to the training data, however they face significant challenges
- Intractable Probabilistic Computations: Approximating the probabilistic computations needed for maximum likelihood estimation is difficult
- Leveraging Piecewise Linear Units: While piecewise linear units are effective in discriminative models, they are harder to apply in generative contexts
- To address these challenges, the authors propose the Generative Adversarial Nets (GANs) framework. In GANs, two models are trained simultaneously:
- Generative Model (G): This model captures the data distribution and generates new samples
- Discriminative Model (D): This model estimates the probability that a sample came from the training data rather than being generated by G
- The training process involves a minimax two-player game where the generator G tries to maximize the probability of D making a mistake, while D tries to distinguish between real and generated samples
- This adversarial setup drives both models to improve continuously
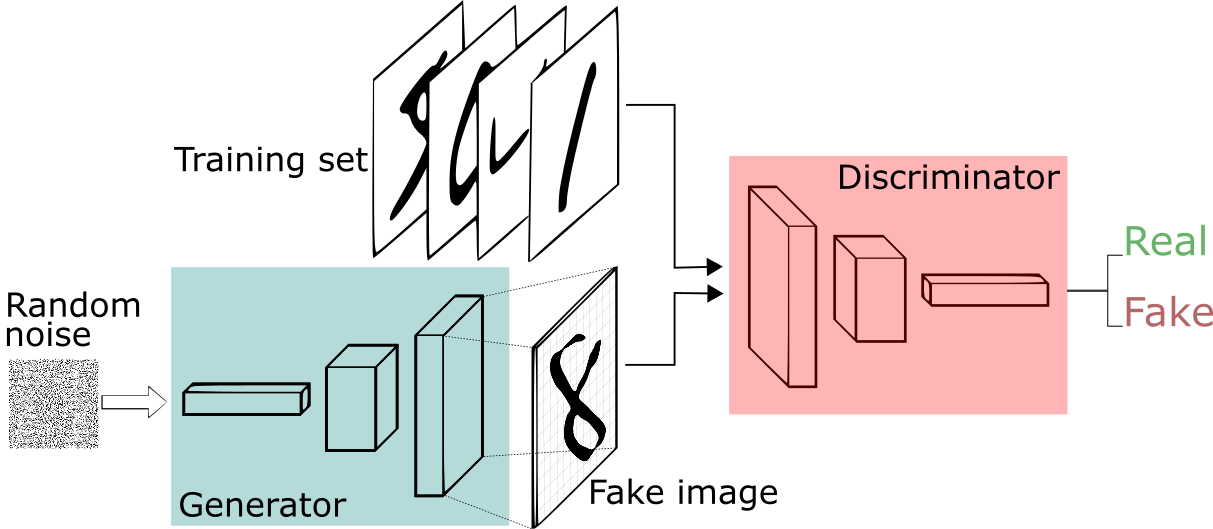 Image Credits: https://sthalles.github.io/intro-to-gans/
Image Credits: https://sthalles.github.io/intro-to-gans/
Adversarial Nets
- The objective is to learn the generator's distribution over data by first defining a prior on input noise variables
- A mapping to the data space is represented as , where is a differentiable function represented by a multilayer perceptron with parameters
- Additionally, a second multilayer perceptron outputs a single scalar representing the probability that came from the training data rather than from
Training Process
- The training involves two competing neural networks:
- Discriminator (): The discriminator is trained to maximize the probability of correctly classifying both real training examples and generated samples from
- Generator (): The generator is trained to minimize , which is equivalent to fooling the discriminator into believing that generated samples are real
- This setup forms a two-player minimax game with the following value function
- :
- The discriminator maximizes this function by learning to assign high probability to real data and low probability to generated samples, while the generator minimizes it by producing samples that the discriminator cannot distinguish from real data
Algorithm

Demo: GAN latent mapping playground
GAN latent mapping playground
A tiny 1D GAN learns a bimodal target distribution at -1 and +1. Slide z to see how the generator maps noise into data space and how the discriminator scores it.
G(z) = 0.000D(G(z)) = 0.500
w = 0.600b = 0.000a = 0.500c = 0.000
Discriminator loss
No updates yet.Generator loss
No updates yet.Real data
Generated
Range: -2.5 to +2.5
This demo trains a tiny 1D GAN on a bimodal target distribution. Slide the latent value z to see how the generator maps noise into data space and how the discriminator scores the generated sample.
- Moving z shifts the generated sample along the line via G(z)=w*z+b, so D(G(z)) changes with it.
- The "Real data" row shows samples from the target distribution (two modes).
- The "Generated" row shows samples from G(z) as training progresses.
- Higher D loss means the discriminator is struggling to tell real from fake.
- Higher G loss means the generator is struggling to fool the discriminator.
- The parameters (w, b, a, c) are the tiny linear weights used by G and D.
What to expect over time:
- Unlike typical supervised learning, both losses don't decrease together
- This is an adversarial game: when the discriminator improves (D loss decreases), it makes the generator's task harder (G loss may increase)
- As the generator improves (G loss decreases), it makes the discriminator's job harder (D loss may increase)
- In a successful training, both losses should stabilize: the discriminator loss around 0.5 (meaning it can't reliably distinguish real from fake) and the generator loss should be low (meaning it's successfully fooling the discriminator)
- The generated samples should gradually match the real data distribution
Code
import torch
import torch.nn as nn
import torch.optim as optim
# Generator: maps noise z to data space
# Simpler architecture: builds up from noise
G = nn.Sequential(
nn.Linear(1, 16),
nn.ReLU(),
nn.Linear(16, 1) # Output: generated sample
)
# Discriminator: classifies real vs fake
# Deeper architecture: needs more capacity to distinguish
D = nn.Sequential(
nn.Linear(1, 32),
nn.ReLU(),
nn.Linear(32, 16),
nn.ReLU(),
nn.Linear(16, 1),
nn.Sigmoid() # Output: probability of being real
)
opt_g = optim.Adam(G.parameters(), lr=1e-3)
opt_d = optim.Adam(D.parameters(), lr=1e-3)
loss_fn = nn.BCELoss()
def sample_real(batch):
modes = torch.randint(0, 2, (batch, 1), dtype=torch.float32)
means = modes * 2 - 1 # -1 or +1
return means + 0.2 * torch.randn(batch, 1)
for step in range(1000):
real = sample_real(128)
z = torch.randn(128, 1)
fake = G(z).detach()
d_loss = loss_fn(D(real), torch.ones_like(D(real)))
d_loss += loss_fn(D(fake), torch.zeros_like(D(fake)))
opt_d.zero_grad()
d_loss.backward()
opt_d.step()
z = torch.randn(128, 1)
fake = G(z)
g_loss = loss_fn(D(fake), torch.ones_like(D(fake)))
opt_g.zero_grad()
g_loss.backward()
opt_g.step()Advantages
- Elimination of Markov Chains
- Traditional methods such as Boltzmann machines rely on Markov chains to generate samples, which can be computationally intensive and slow due to the need for long mixing times
- In contrast, GANs use direct backpropagation to obtain gradients, making the training process more efficient
- No Need for Inference During Learning
- In traditional generative models, inference is often needed to approximate the posterior distribution of latent variables which can be complex and computationally expensive
- GANs bypass this requirement entirely, as the generator and discriminator networks are trained directly to optimize their respective objectives without the need for such inference procedures
- Flexibility in Model Design
- GANs offer a high degree of flexibility because any differentiable function can theoretically be incorporated into the model
- This allows for a wide variety of architectures and activation functions to be used, enabling researchers to tailor the model to the specific requirements of their data and task
- Strong Gradients and Better Learning
- The generator in a GAN is updated using gradients that flow through the discriminator
- This indirect method of updating the generator can provide strong gradients, especially early in the training process, when the generator might otherwise struggle to learn effectively
- This can lead to more stable and faster convergence in many cases
Disadvantages
- No Explicit Representation of
- The generator only learns an implicit mapping from noise to data through the function , without defining a tractable density function
- This makes it challenging to evaluate the quality of the generated samples quantitatively, as there is no straightforward way to calculate likelihoods or other probabilistic metrics directly from the model
- Synchronization Challenges
- The training process of GANs requires careful synchronization between the generator (G) and the discriminator (D)
- If the generator is trained too much without updating the discriminator, it can lead to issues such as the "Helvetica scenario," where the generator collapses to producing only a few modes (i.e., it generates very similar samples regardless of the input noise)
- This lack of diversity is a critical issue that needs to be managed during training
- Computational Stability
- Training GANs can be unstable, as it involves finding a balance in a minimax game between the generator and the discriminator
- Small changes in the training dynamics can lead to significant instability, requiring careful tuning of hyperparameters and potentially sophisticated training techniques to maintain stability