BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
BERT (Bidirectional Encoder Representations from Transformers) pre-trains deep bidirectional transformer encoders using Masked Language Modeling (MLM) and Next Sentence Prediction (NSP) to learn contextual word representations that can be fine-tuned for various NLP tasks, achieving state-of-the-art results without task-specific architectures.
Paper Link
Key Definitions
| Term | Definition |
|---|---|
| ELMo (Embeddings from Language Models) | - ELMo (Embeddings from Language Models) is a pre-trained language representation model introduced by Peters et al. in 2018 - It is designed to improve the performance of natural language processing (NLP) tasks by providing deep contextualized word representations - Unlike traditional word embeddings like Word2Vec or GloVe, which provide a single static representation for each word, ELMo generates dynamic word embeddings that change depending on the context in which the word appears - ELMo is based on bidirectional LSTM (BiLSTM) networks, which means it processes text in both forward and backward directions - In the feature-based approach, ELMo embeddings are used as additional features in task-specific models |
Introduction
- There are two main strategies for applying pre-trained language representations to downstream tasks
- Feature-based approach: This includes methods like ELMo, where pre-trained representations are incorporated as additional features into task-specific architectures
- Fine-tuning approach: Exemplified by OpenAI GPT, this strategy involves minimal task-specific parameters, and the pre-trained model is fine-tuned on the downstream tasks
- Limitations of Current Pre-training techniques
- Current fine-tuning approaches typically employ unidirectional language models (left-to-right or right-to-left), which limits the model's ability to incorporate full context from both directions
- This unidirectionality constraint can be suboptimal, especially for tasks like question answering, where understanding the context from both directions is crucial
BERT
- BERT addresses the limitations of previous models by pre-trainign deep bidrectional representations
- The two main innovations in presented in BERT are the Masked Language Model (MLM) and Next Sentence Prediction (NSP)
Model Architecture
- BERT’s architecture is a multi-layer bidirectional Transformer encoder based on the original implementation
Masked Language Model (MLM)
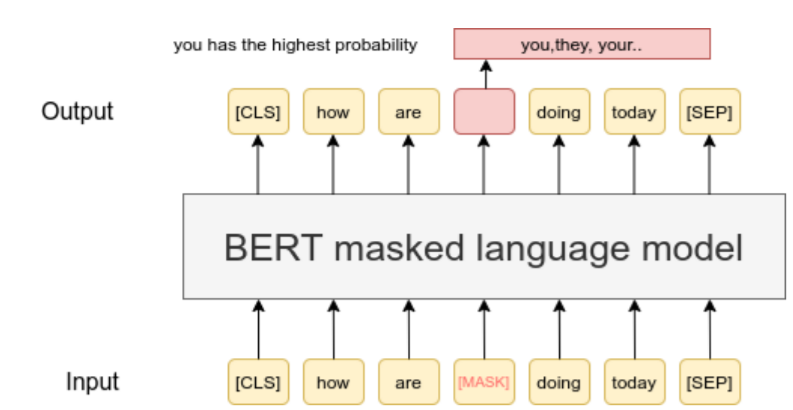
- Traditional left-to-right language models predict the next word in a sequence
- In contrast, BERT uses MLM, where some percentage of the input tokens are masked at random, and the model attempts to predict these masked tokens based on their context
- Specifically, 15% of tokens are randomly masked. Of these, 80% are replaced with the [MASK] token, 10% are replaced with a random token, and 10% remain unchanged
- This approach enables the model to learn bidirectional representations
Demo: MLM masking playground
MLM masking playground
Sample which tokens are masked and how the 80/10/10 corruption rule changes the input seen by the model.
| # | Original | Corrupted input | MLM label |
|---|---|---|---|
| 1 | The | The | — |
| 2 | quick | [MASK] | quick |
| 3 | brown | brown | — |
| 4 | fox | fox | — |
| 5 | jumps | [MASK] | jumps |
| 6 | over | dog | over |
| 7 | the | the | — |
| 8 | lazy | lazy | — |
| 9 | dog | dog | — |
Use the slider to change the mask rate and see the 80/10/10 corruption rule in action.
Next Sentence Prediction (PSP)
- To improve understanding of sentence relationships, BERT also incorporates a next sentence prediction task
- For each training example, 50% of the time the second sentence is the actual next sentence (labeled as IsNext), and 50% of the time it is a random sentence from the corpus (labeled as NotNext)
- This task helps the model understand the context beyond individual sentences
Demo: Next sentence prediction playground
Next sentence prediction playground
Toggle between IsNext and NotNext to see how sentence pairs and labels are constructed.
Switch between IsNext and NotNext to see how sentence pairs and labels are formed.
Fine-tuning BERT
- Unified Architecture:
- BERT’s architecture remains largely unchanged during fine-tuning, apart from task-specific output layers.
- The model is fine-tuned end-to-end, with all parameters adjusted based on the specific task’s labeled data.
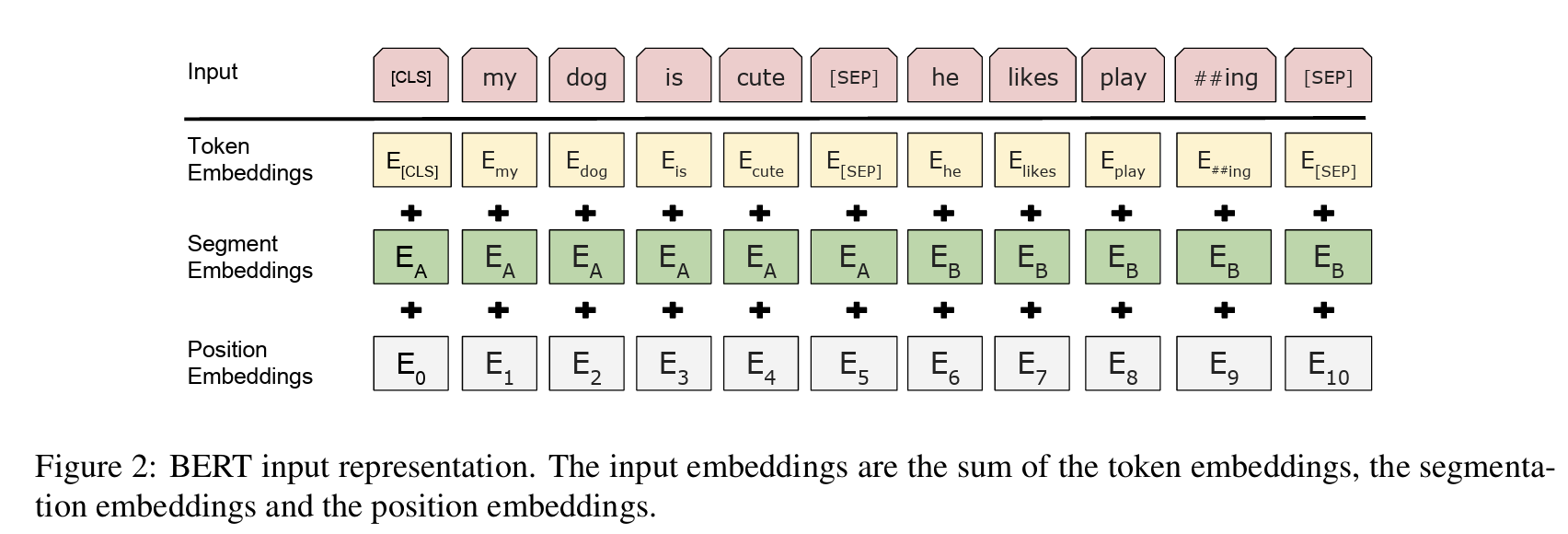
- Token Embeddings: WordPiece embeddings with a 30,000 token vocabulary are used.
- Segment Embeddings: Differentiate between two sentences in a single sequence by adding learned embeddings.
- Position Embeddings: Capture token positions within the sequence.
- [CLS] Token: A special classification token added at the beginning of each sequence. Its final hidden state is used for classification tasks.
- [SEP] Token: A separator token used to distinguish between different sentences in a sequence.
Demo: Input representation builder
Input representation playground
Inspect how token, segment, and position embeddings combine for a selected token.
| Index | Token | Segment | Position |
|---|---|---|---|
| 0 | [CLS] | 0 | 0 |
| 1 | Where | 0 | 1 |
| 2 | do | 0 | 2 |
| 3 | penguins | 0 | 3 |
| 4 | live | 0 | 4 |
| 5 | [SEP] | 0 | 5 |
| 6 | They | 1 | 6 |
| 7 | live | 1 | 7 |
| 8 | in | 1 | 8 |
| 9 | the | 1 | 9 |
| 10 | Southern | 1 | 10 |
| 11 | Hemisphere | 1 | 11 |
| 12 | [SEP] | 1 | 12 |
Click a token to inspect its segment ID, position index, and the embedding sum.
- Task-specific Fine-tuning:
- Single Sentence and Sentence Pair Tasks:
- For single sentence tasks, the input representation is the token sequence of the sentence.
- For sentence pair tasks, the input representation is the concatenation of the token sequences of both sentences, separated by the [SEP] token.
- The [CLS] token representation is used as the aggregate sequence representation for classification tasks.
- Single Sentence and Sentence Pair Tasks:
- Examples of Fine-tuning for Specific Tasks:
- Question Answering: The question and passage are concatenated into a single sequence. Special start and end vectors are introduced during fine-tuning to predict the answer span within the passage.
- Text Classification: The final hidden state of the [CLS] token is fed into a classification layer to predict the class label.